Traces Week 19 - 2023
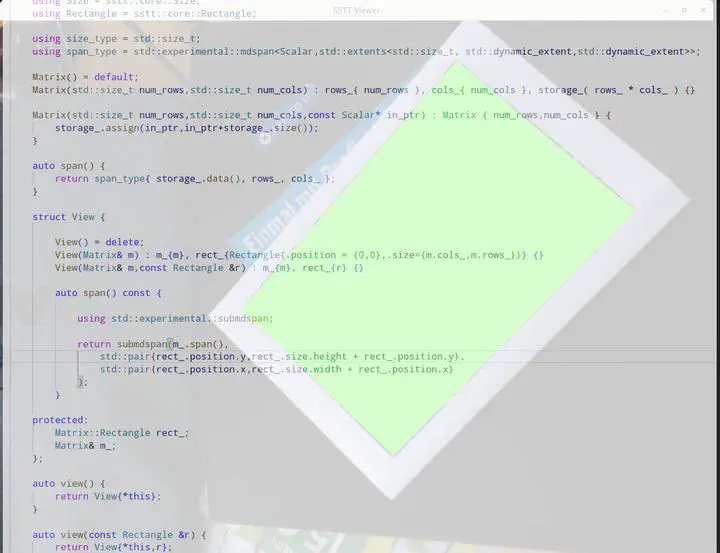
After an inexcusable long hiatus, I wanted to share some insight into current development work for SSTT, which I hope to release by end of the year under an open source license. After revisiting the large codebase and working tediously to migrate code to C++20 and having a glimpse at C++23, one thing caught my eye - ranges! In C++23 the functional paradigm <ranges> API in STL got a rather substantial upgrade. However, I tend to be a bit more academic before jumping on such a theme, after all SSTT needs to be fast. As it turns out, beyond auto operator [] (int,int ...) aka. multidimensional de-referencing operator, <mdspan> is a huge and seemingly complex piece of code that will eventually ship with future C++ toolchains.
SSTT undergoing major surgery on the very foundation, especially to optimize internal data representations, std::mdspan and friends were a promising alley to investigate. Let me share with you some of my insight.
Implementation
My custom sstt::core::Array<> CRTP is obviously everywhere in the code. It represents images, textures, auxiliary buffers, point clouds etc. pp. It is for a reason a core system concept. And there are many good reasons to replace the old implementation, with non-optimal element access being one of them.
First I went on to decode the way std::mdspan is actually converting spatial operations into a linear concept. Honestly, the API examples are not yet very useful, it took me a while to decode the actual apis of std::mdspan and std::submdspan. For this I used the single header pre-release of the Kokkos <mdspan.hpp> here.
Target Scenario
My attempt was to replace and unify operations on contiguous and non-contiguous data (mostly images but also other operations) in sstt::core::Array<>
System
My test system was a i7 8700 (12 Cores), NVIDIA GTX 1070 with 16GiB RAM on a ArchLinux gcc (GCC) 13.1.1 20230429 with release Mode, hence -O3 and -std=c++23 were on. No TBB, because for those kind of operations I prefer single threaded performance measurements as the overarching pipelining system in SSTT will schedule things across cores, and there are lots of things going on. Putting additional CPU pressure for low-level operations is not that useful. However, proper vectorization and cache-line optimization can help a lot.
Measurements
Manual (is_contiguous() == true)
Arrays FullHD Mean 100 1 17.48 ms
173.909 us 172.452 us 176.058 us
8.87194 us 6.40105 us 11.9164 us
mdspan () contiguous data but no check
Arrays FullHD Mean 100 1 111.946 ms
1.11522 ms 1.10776 ms 1.12618 ms
45.5794 us 33.6912 us 59.4841 us
one reason - seems cache misses (simple perf stat)
mdspan() branch-misses:u # 0,40% of all branches
manual branch-misses:u # 0,26% of all branches
Conclusion
Semantically std::mdspan is an absolute beauty. Just look at this:
// wrapper around data structure
auto m = Matrix<uint8_t>{1920, 1080};
// lambda for sum
auto sum = [](auto s) {
using T = decltype(s)::value_type;
decltype(T() + T()) sum {0};
const auto r = std::views::cartesian_product(
std::views::iota(0u,s.extent(0)), // u suffix because template
std::views::iota(0u,s.extent(1)) // deduction sees a size_t
);
std::ranges::for_each(r.begin(),r.end(),[&s,&sum](auto idx) { auto [r,c] = idx; sum += s[r,c]; } );
return sum;
};
// lambda for mean
auto mean = [&](auto s) {
return sum(s) / (s.extent(0) * s.extent(1));
};
// thats it ...
auto res = mean(m.span());
// ... and that where the power of mdspan and submdspan comes in handy
auto res = mean(m.view(Rectangle{Position{10,20},Size{16,16}).span());
It almost feels a bit like Rust. But yes, there are other tools in <algorithm> such as std::accumulate to achieve this, but they know nothing about 2D or 3D arrays and especially not strided views into them (or sliced if you come from HPC). For now I can live with a small proxy template to branch out for non-contiguous data (views).
The overhead introduced by std::mdspan and friends, is seemingly heavy and I am not sure if that is my fault or the preliminary implementation I am using. My approach is a hit-and-miss interpolation from various documentation resources and spurious examples I found and therefore by no means perfect. But my slightly informed guess is, that the access over both extents creates quite some cacheline misses with computer vision typical small images. So, I’m not closing the book on std::mdspan - just for my particular purpose here it seems not a good fit. I have moved my implementation into a new sstt::core::experimental namespace to revisit later.
Over time, and if more people are using it, an improved documentation and examples will pop up, paper-cuts will be removed and maybe I can then get rid of my custom handling of multidimensional data structures.
References
- https://github.com/kokkos/mdspan
- https://www.ashermancinelli.com/std-mdspan-tensors
- https://github.com/kokkos/mdspan/wiki/A-Gentle-Introduction-to-mdspan
- https://cppcast.com/too-cute-mdspan/
- this is where I understood how “strides” are “slices” in HPC land … https://youtu.be/aFCLmQEkPUw?t=1108
Hartmut Seichter
Professor of Computer Graphics
My research interests are Augmented and Virtual Reality in combination with Tangible User Interfaces.